What’s the point?
It’s estimated that the human race spends over $3.5 trillion annually on IT. The world’s largest companies invest billions in tech driven change each year. But do we know how effectively we’re investing that money? Do we know if those investments are adding the intended – indeed, any – value? Do we know if our software deliveries are hitting the mark, or missing the point?
Feedback, introspection and adaptation based on learning are critical in improving things; measurements matter. To drive continuous improvement, mature software development teams will focus on 3 categories of measurement above all others – flow of work, quality of work and value.
Measurements of flow and quality have become more consistent over time, with teams monitoring lead and cycle time, throughput, MTTR, SLO adherence / error budgets and so on in similar ways.
True value measurements, however, are still generally absent from these metrics systems, and those of larger corporate investment governance structures. Teams often resort to proxies for value; story points delivered, relative value points or feature throughput as examples.
Others don’t even go this far, and rely instead on ‘software delivered on time and on budget’ as a primary indicator of successful work. There are a myriad of problems with this; the dysfunction surrounding estimation is one (discussed in another post on #RangedEstimates); the fact that the simple act of delivering software (or making process change, or any other type of change) doesn’t actually prove that anything good happened is another. All that meeting ‘software delivery’ milestones tell us with confidence is that some software was delivered.
There are reasons for the absence of commonly observed value metrics.
Measuring value isn’t straightforward; value lags any activity which was intended to deliver it and is often loosely correlated to change delivery. Revenue increases or expense reductions may not show themselves for months or quarters after a product is enhanced, and other factors can obscure the causality between input (effort spent), output (software) and outcome (value), for example changes in market conditions or competitor actions.
So what is Value?
Meaningful prioritisation requires us to estimate the value of a given piece of work. Investment propositions are generally thought of as single step hypothesis…
“If we invest to deliver x, we believe we will realise value y”
…where y could be a revenue increase, an expense reduction, or some other tangible value which would make the investment in x seem worthwhile. This could be a tiny feature, deliverable in a matter of hours or the opening up of a whole new product or market, delivered over multiple weeks, months or quarters.
In truth, there is always something in between the delivery of change and value being realised. There are always at least two, separable hypothesis. The missing link in between ‘change’ and ‘value’ is important to understand if we’re interested in leading indicators of progress towards value.
We’ll call the missing link ’impact’, and rewrite our value statement as follows…
“If we invest to deliver x, we believe there will be an impact, y” (first hypothesis)
“When y happens, we believe that we’ll be able to realise value z” (second hypothesis)
Impact is the thing which links change to value. Impact Metrics are what we measure to determine if the first hypothesis was true.
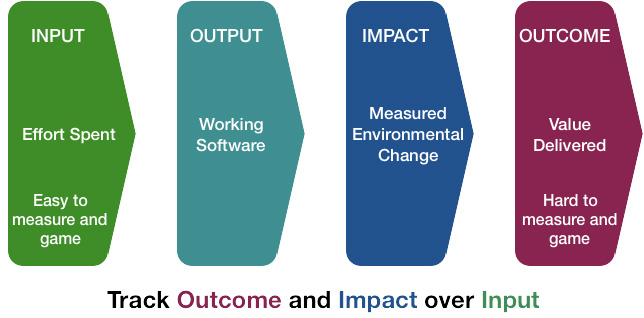
(thanks @annaurbaniak_me for the graphic)
Impact Metrics
Impact Metrics are a way of calling out the expected impact that an investment will make on the world, from which value might be derived. These metrics should be observable and measurable, ideally in an automated way. These metrics should be a primary data point when considering whether progress is being made, or not.
One of the principles in the Agile Manifesto states “Working software is the primary measure of progress”. Good teams will extend the meaning of ‘working’ beyond ‘it compiles’ or ‘it doesn’t give me a HTTP 500 when I click the Submit button’, to mean ‘it solves the problem for which it was designed’.
Or maybe it doesn’t. That will inevitably happen. Impact Metrics provide insight here, too. Delivery of the wrong solution “on time and on budget”™ helps no-one, but is often celebrated as a success. Realising that the awesome updates we just made to our online store actually reduced – rather than increased – customer conversion rates might hit hard, but is obviously important if we’re to get to better outcomes.
Test Driven Products
It’s interesting to observe how Impact Metrics (done well) yield similar benefits for products and projects to the ones Test Driven Development (done well) yield for codebases:
- TDD requires that you to think hard about the problem you’re trying to solve before embarking on any change, such that you can articulate clearly the expected outcome of the change
- TDD requires that you make the success criteria of the work you’re about to embark on transparent, explicit and measurable
- TDD requires that you create a system that is inherently testable
- TDD makes the success (or failure) of an implementation against those tests immediately transparent to all
- Over time, TDD creates a system of feedback to show if new changes break expected legacy behaviour in other parts of the system
All of these benefits apply when Impact Metrics are used in the right way, as you must…
- …define the desired impact of an investment or change up front, including how it will be measured, and describe how these measures are expected to change over time
- …make these measures transparent; these are the impact that everyone is working to achieve, and from which someone will derive his or her value
- …start to monitor these measures, ideally in an automated way and prior to any change being delivered in order to understand the baseline
- …pay attention to the impact metrics as change is delivered (ideally in frequent, small batches) to see if they start to move in the predicted direction – remember that this is our real measure of progress, and is an important source of feedback and learning
- Note that Impact Metrics often have value beyond the completion of the specific change which introduced them. They should be maintained as you would a normal test suite, discarding them only when they no longer assert something which has relevance
This last point is especially interesting. In the future, something may change which reverses the impact you delivered previously, and the original value may start to deteriorate. This could be due to something we did, or some external factor. Keeping these metrics ‘live’ is a good way of ensuring you can see when your product / value stream is ‘broken’, in the same way a good build radiator does for a code base.
This leads us to a world of Testable Products or Projects, where real progress towards desired outcomes can be measured and made transparent, and where deviations against expected or predicted behaviour can be alerted to and acted upon.
We’re all standing on the shoulders of others…
None of the above is new, indeed, the best technology led product companies in the world do this routinely.
What I’m constantly amazed by, however, is how many large enterprises lack this level of attention to detail in measuring the impact of the change investments they make, or in electing whether to continue to apportion funds to ongoing investments.
Individual and Interactions over Process and Tools
I’ve seen Impact Metrics make a material difference to the types of conversation teams have with their customers, business partners and sponsors; how teams understand their customer needs, and how real progress is measured and celebrated.
Impact Metrics get the team and sponsors aligned on what the real purpose of the work is. Most businesses don’t care about Epics, Features, Story Points, MVP’s, PSPI’s, Release Trains or Iterations. They use these terms only because we’ve asked them to. They care about sales, active customer or user numbers, conversation rates, product or order lead times, levels of customer complaints or satisfaction, social media sentiment, idle inventory, product defect / return rates and anything else which drives the thing they care about more than anything else – sustainable positive margin between revenue and expense.
Teams are not paid to deliver software, they are paid to deliver impact from which value can be derived. Software done well (small batches, delivered continuously) can be a great tool for this, but on it’s own is not the point. As Dan North often says, if you can achieve impact without having to change software, you are winning at software (h/t @tastapod).
There are other interesting side effects I’ve observed in teams using these techniques. Shaving functional scope to hit arbitrary dates occurs less because, as a consequence, the transparently measured impact gets diminished. If you’re delivering in frequent increments, you’ll know up front if the full desired impact is more or less likely to occur, and make decisions much earlier on how to modify your approach or investment.
Impact Metrics also create a cleaner separation of accountabilities between delivery teams and business sponsors. This may seem bad, or even controversial. However, bear with me…
Practically speaking, it’s often difficult or unrealistic for a delivery team to be genuinely accountable for resultant value in a corporate environment, even if they desire that accountability. There are often other important cogs in the system which determine whether the impact – if delivered – actually gets fully converted into value….sales and marketing teams are an obvious example.
It’s also important that the customer / business sponsor / stakeholder feels accountable for the resultant value of an investment. In my experience, it benefits if sponsors have real skin in the game – the accountability of turning delivered impact into value best sits firmly on the shoulders of the person accountable for the financial performance of a product or business area.
A delivery team should always be aware of, be able to question, challenge and ultimately understand the connection between impact and value. But once that’s accepted, the team can focus on delivering impact – not software. The business / product owner can focus on ensuring that the value is subsequently derived from impact as it gets made. Everyone can see, from how impact metrics move as changes are made, whether the first hypothesis is still holding true, and adjust. Maybe the impact is harder to get to than first thought; it might make sense to stop investing.
This separation of accountabilities may be undesirable in some circumstances, such as product companies whose primary product is technology but in corporates whose business is something which is enabled by, rather than actually being, technology, it can be beneficial. Feel free to argue this, or indeed, any other point – all debate welcome 🙂
Scaling Impact Metrics
There is one common problem for Enterprises when it comes to applying Impact Metrics – aggregation.
Large companies often collect metrics in a consistent way across businesses and aggregate them, to provide ‘Top of the House’ views. Impact Metrics don’t suit this type of aggregation, as they are necessarily domain specific.
To anyone looking at how this model might apply at company scale, I’d offer this advice
- Ensure that, for any material investment you’re making, as well as capturing “Spend x, Make z”, you also capture “the impact of spending x will be demonstrated by impact measures y1, y2, y3”
- Ensure every investment you make has an identified business / product owner or sponsor who is accountable and will stand behind the second hypothesis “If impacts y1 – y3 occur, I will be able to derive value z”
- Identify how many investments can’t articulate either of these, and understand whether that’s a concern – you may have a case of underpants gnomes
If you do have to produce aggregated enterprise measures, make visible the percentage of investments (and the total spend of those investments) for which there is no transparent measure of impact / success, or for which there is no accountable party will to stand behind the link between delivered impact and value. Go and ask some searching questions of those investments.
For everything else, make positive trend towards impact the key measure of progress. The teams can deal with everything else.
I’d love to hear other’s views (or even better – experiences), here or on Twitter @hamletarable. No silver bullets offered here, just another tool for the toolbox which has helped me, and others I’ve observed, deliver better outcomes in their contexts. Keen to understand if this applies in the context of others, and where it doesn’t.
Other posts I love on this topic
https://dannorth.net/2013/07/05/are-we-nearly-there-yet/ – by the awesome @tastapod
https://gojko.net/2012/05/08/redefining-software-quality/ – by the equally awesome @gojkoadzic
https://www.infoq.com/articles/impact-portfolio-management-agile – by awesome ex teammates @TommRoden and @13enWilliams
